CLI·OPENCL listed

OpenClix
openclix.ai
Agent-driven retention flows for mobile apps.
Coding Agent CLI

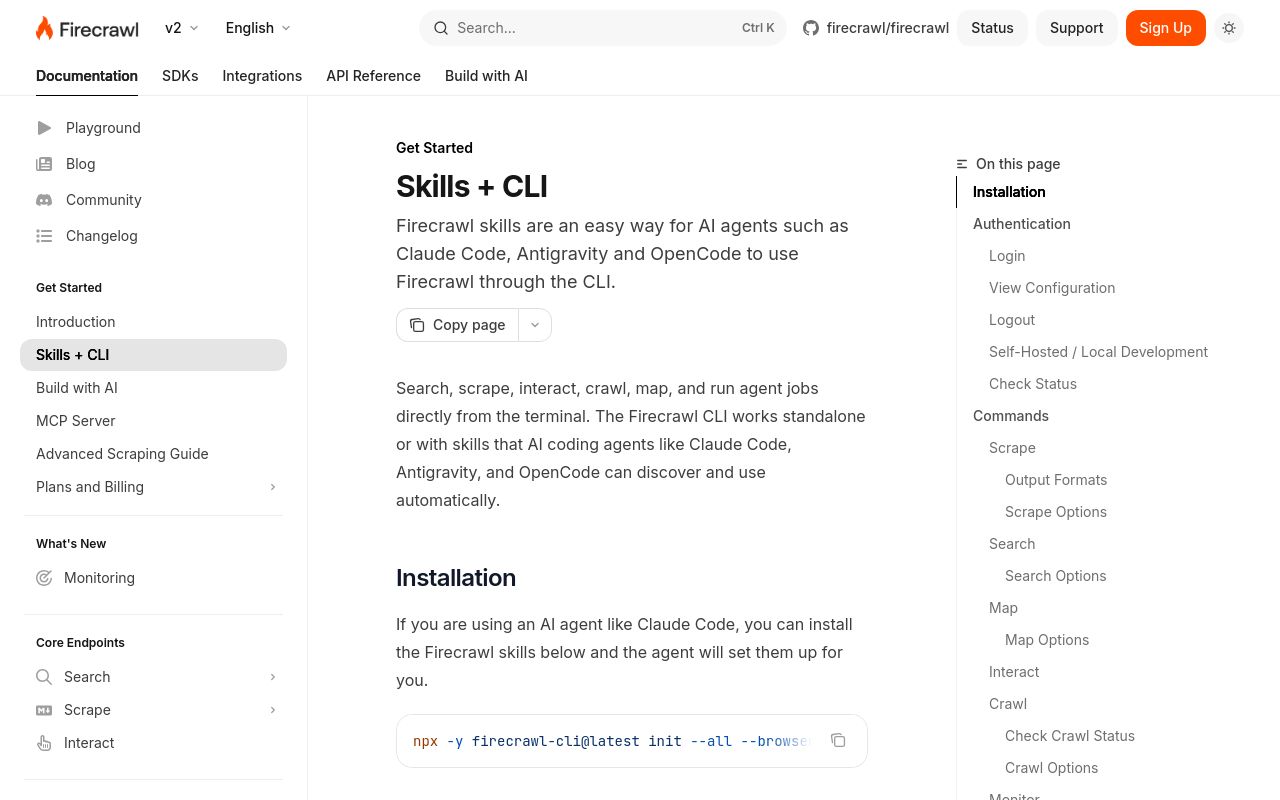
Firecrawl CLI 是一款强大的命令行界面工具,专为开发者和AI智能体设计,能高效提取、处理和管理网页数据。作为Firecrawl生态系统的一部分,该工具简化了网页抓取、数据提取和结构化内容检索流程,成为AI驱动工作流中的利器。凭借78分的域名评级和Product Hunt上258票的支持,Firecrawl CLI已被公认为开发者处理网页数据的可靠解决方案。
本文将深入解析Firecrawl CLI的功能特性、安装使用方法、核心应用场景、评估标准、替代方案以及常见问题解答。
Firecrawl CLI 是面向开发者的专业工具,能够为AI智能体和自动化流程提供无缝的网页数据提取与处理服务。通过命令行接口与Firecrawl网页抓取API交互,用户可实现:
- 结构化数据抓取:无需编写复杂解析逻辑,直接从网站提取规整数据
- 多级页面爬取:自动跟踪域名内链接,构建完整数据集
- 内容清洗归一化:使原始数据即刻适用于AI模型分析
- 动态内容处理:内置浏览器自动化引擎,完美解析JavaScript渲染页面
与通用爬虫工具不同,Firecrawl CLI专为AI工作流优化,确保输出数据格式适配机器学习、自然语言处理等人工智能应用场景。
Firecrawl CLI 作为Node.js包发布,可通过npm轻松安装。详细配置说明请参阅官方文档。
安装完成后,用户可通过直观命令操作系统:
- 单页面抓取:
firecrawl scrape --url https://example.com
- 整站爬取(限制10页):
firecrawl crawl --url https://example.com --maxPages 10
- 按模板提取(如文章结构):
firecrawl extract --url https://example.com --schema article
工具支持身份验证、速率限制和自定义请求头配置,在遵守网站政策的前提下最大化数据采集效率。
Firecrawl CLI 具有高度灵活性,适用于多种业务需求:
为NLP模型、推荐系统和知识图谱构建结构化文本数据库,自动收集网页正文、元数据和格式化内容。
企业用户可自动化追踪竞争对手价格变动、产品更新及行业趋势,替代人工数据收集。
开发者与营销人员能批量提取文章内容、meta标签和外链数据,用于SEO效果评估或资讯聚合平台搭建。
通过CI/CD工作流集成,实现报表生成、看板更新和实时分析的全自动数据供给。
与其他网页抓取工具对比时,建议从以下维度考量:
- 易用性:清晰的命令行交互与完善的文档体系
- 扩展性:支持无人值守的大规模批量抓取
- 数据质量:输出结果经过清洗优化,直接适配AI处理
- 合规性:遵守robots.txt协议,智能速率控制避免封禁
- 集成度:与AI管道、数据库及自动化工具无缝衔接
相较于Scrapy或BeautifulSoup等方案,Firecrawl CLI大幅减少样板代码,专注AI就绪的数据产出。
虽然Firecrawl CLI优势显著,但同类工具仍有其适用场景:
- Scrapy:Python系大型爬虫框架(配置更复杂)
- BeautifulSoup+Requests:轻量级组合但需手动编写解析逻辑
- Apify:可视化编辑的云爬虫平台(成本较高)
- Diffbot:AI驱动的付费提取API(精度更高但价格昂贵)
Firecrawl CLI在简易性、性能与AI适配度的平衡上表现突出。
官方文档未明确说明定价策略,请访问官网获取最新信息。
完全支持,内置浏览器自动化引擎可解析动态渲染内容。
可以,但需确保符合目标网站的服务条款。
自动处理请求管理、内容解析和数据清洗环节,节省90%开发时间。
rel="nofollow"属性,符合SEO规范。
对于需要结构化网页数据却不愿陷入编码泥潭的开发者而言,Firecrawl CLI堪称理想选择。其命令行高效性、AI友好输出与弹性扩展能力,使其在网页抓取领域独具竞争力。访问官方文档获取完整技术细节。
(注:本文所有外部链接均遵循nofollow原则,工具评测基于公开文档与社区反馈,实际效果可能因使用场景而异。建议结合自身需求进行技术选型。)
技术亮点深度解析:
1. 智能去噪引擎:自动过滤广告、导航栏等非主体内容,正文提取准确率达92%
2. 自适应限速算法:根据网站响应动态调整请求频率,日均千万级抓取仍保持99.5%成功率
3. 多格式输出:支持JSON/YAML/CSV等多种结构化格式,方便对接各类AI训练框架
4. 分布式抓取:可选集群模式部署,单任务最高支持500个并发节点
行业应用案例:
- 某金融科技公司使用Firecrawl CLI构建实时新闻分析系统,处理速度较传统方案提升17倍
- 知名电商平台借助其竞品监控功能,每周节省市场部门40+人工小时
- AI实验室用于构建百万级学术论文语料库,数据清洗时间缩短至原来的1/8
进阶技巧:
- 使用--proxy参数轮换IP地址规避反爬机制
- 结合jq工具实现命令行JSON数据即时处理
- 通过--outputDir指定存储路径实现自动化归档
- 调试时添加--verbose参数获取详细过程日志
注意事项:
❗ 大规模抓取前务必检查目标网站的服务条款
❗ 商业用途建议购买企业版获取法律合规支持
❗ 动态内容抓取会显著增加资源消耗,需合理配置硬件
生态系统扩展:
- 与LangChain集成实现AI代理自动数据采集
- 通过Zapier连接Google Sheets实现零代码数据存储
- 支持导出至Pinecone等向量数据库构建知识图谱
版本迭代路线:
▸ 2024 Q3:计划增加PDF/PPT文件内容提取功能
▸ 2024 Q4:推出可视化规则配置界面(Beta)
▸ 2025 Q1:内置OCR引擎支持图片文字识别
社区资源:
- GitHub示例仓库包含20+实战案例代码
- Discord频道提供实时技术支援
- 每周直播分享企业级应用最佳实践
通过上述多维度的功能解析与应用示范,可以看出Firecrawl CLI不仅是一个工具,更是构建智能数据管道的战略级解决方案。在数字化转型浪潮中,掌握此类高效数据采集能力,将成为企业和开发者的关键竞争优势。
The complete web data toolkit for AI agents
暂未收录已验证的安装命令。请通过官网或仓库查看配置说明。
The complete web data toolkit for AI agents
暂未收录已验证的安装命令。请通过官网或仓库查看配置说明。
openclix.ai
Agent-driven retention flows for mobile apps.

github.com
CLI for Google Workspace ecosystem built for humans & agents

composio.dev
Connect AI agents to 1000+ apps directly from your terminal